Homework 1
In this first homework, you will be training a deep network to classify images from SuperTuxKart.
This assignment, as with all of the homework assignments, should be completed individually without sharing solutions, models, or ideas with other students. See details at the bottom of this page.
Running on Google Colab
For this assignment, as well as future assignments, you may want access to a GPU to train your models more quickly. You can get access to a GPU through Google Colab using the following iPython notebooks:
- An extensive one, for the first couple times you use Colab, or
- A pared-down one to use once you are comfortable with the workflow.
In order to use these notebooks, go to http://colab.research.google.com, sign in, then select upload. Upload the notebook you want to use, then follow the instructions in the notebook.
Code
We provide some starter code for this homework here. This zip file contains the following:
bundle.py, a script you can use to zip up your homework for submission. In order to submit your homework, runpython bundle.py homework <uteid>which will create a file called<uteid>.zip. This is the file you should submit.gradercontains a local grader which you can use to evaluate your homework and see what grade you would currently get. Note that the local grader and our grader use different test sets, so this grader is not guaranteed to be 100% accurate.homeworkcontains the code you will modify for this assignment.datais a placeholder which will be replaced by the dataset for this assignment.
You can run the local grader at any time by using the following command:
python -m grader homework -v
You will need to separately download the SuperTuxKart dataset.
You can unzip that file into the root directory to replace the existing data
folder. After unzipping you should see subfolders train and valid inside
the data folder. The reason the data is provided separately is because we will
use this dataset for future homeworks as well. In those assignments you can
simply symlink the data folder in order to avoid wasting storage space.
Data Loader (15 pts)
The first thing you will need to do is finish implementing the data loader for
the SuperTuxCart dataset. Inside homework/utils.py, you will find the
SuperTuxDataset class. You will need to implement the following methods:
__init__should initialize the dataset.__len__should return the size of the dataset.__getitem__should return a tuple of image, label. The image should be a tuple of shape(3, 64, 64)while the label should be an integer. Note that each pixel value should be normalized to the range [0, 1]
The labels for each image are saved in labels.csv. This is a CSV file with
headers file and label where file indiates a filename and label holds
the corresponding label. There are six labels for this dataset. Note that in
order for the grader to work, you should use the following map from text labels
to integers: background - 0, kart - 1, pickup - 2, nitro - 3, bomb - 4, and
projectile - 5.
Once you have finished implementing the data loader, try running
python -m homework.visualize_data data/valid
in order to visualize a few images from each class.
Here are a few hints for this section:
- The Python standard library includes the
csvpackage, which can be used to easily read CSV files. - Remember from class that
torchvision.transforms.ToTensor()can help you convert aPIL/Pillowimage to a tensor. - There are at least two ways to implement the data loader: You can load all of
the data in
__init__or you can load datapoints one at a time in__getitem__. If you load all of the data up front, remember to convert them to tensors in order to avoid an OS error for having too many open files.
Some documentation you might find useful:
- torchvision.transforms.ToTensor
- torch.utils.data.Dataset
- csv, particularly csv.reader
- PIL.Image.open
Linear Model (15 pts)
For this section, you will implement the LinearClassifier class in
homework/models.py. You will define the model architecture in the __init__
function, then implement forward. The forward function should take a (B, 3, 64, 64) tensor as input and return a (B, 6) tensor as output, where each
input image is associated with a value for each class.
You will receive the full 15 points for this section simply for defining the model – these points do not depend on accuracy or training.
Some documentation:
Loss Function (10 pts)
In this section, you will add a loss function which can be used to train your
model. To do this, implement the ClassificationLoss class in
homework/models.py. This loss should be the negative log-likelihood of a
softmax classifier:
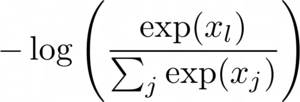
You can do this using existing PyTorch functions. Take a look in torch.nn.functional.
Training the Linear Model (30 pts)
Now we are ready to implement the training procedure for your linear model. To do this, you will need to
- create a model, a loss, and an optimizer;
- load the data;
- run several epochs of SGD; and
- save your model with
save_model
There is a skeleton for this procedure in homework/train.py. Once you are
ready to train, you can run your code with
python -m homework.train -m linear
A couple of hints:
- You may want to use
ArgumentParserto add some hyperparameters to the command line so you can quickly experiment with them. - You may wish to load and continue training with an existing model. See the
load_modelfunction. - Write your training code in a way that works with any model. We will use it with a different model in the next section.
Some documentation:
MLP Model
In this section we will switch out the linear model for a more powerful
multi-layer perceptron model. Implement the MLPClassifier class in
homework/models.py. This class has the same interface as LinearClassifier.
Now train the model with
python -m homework.train -m mlp
Some hints:
- You may need to tune your training code. Try moving hyperparameters to the
ArgumentParser. - Use ReLU as your nonlinearities.
- Two layers is enough for this assignment.
- Keeping the first layer small reduces the number of parameters.
Some documentation:
Grading
The test grader can be run with
python -m grader homework -v
Note that this grader is using a different set of test data than we use for our grader, so there may be some difference between the two. The distributions will be the same so your grade should be similar between the two graders, unless the model is massively overfit to the validation set.
Submission
Once you are ready to submit, create a bundle by running
python bundle.py homework <eid>
then submit the resulting zip file on Canvas. Note that the grader has a maximum file size limit of 20MB. You shouldn’t run into this limit unless your models are much larger than they need to be. You can check that your homework was bundled properly by grading it again with
python -m grader <eid>.zip
Online Grader
The online grading system uses a slightly modified version of Python, so please make sure your code follows these rules:
- Do not use
exitorsys.exitas this will likely crash the grader. - Do not try to access files except for the ones provided with the homework zip file. Writing files is disabled.
- Network access is disabled in the grader. Make sure you are reading your
dataset from the
datafolder rather than from a network connection somewhere. - Do not fork or spawn new processes.
printandsys.stdout.writeare ignored by the grader.
Honor Code
You should do this homework individually. You are allowed to discuss high-level ideas and general structure with each other, but not specific details about code, architecture, or hyperparameters. You may consult online sources, but don’t copy code directly from any posts you find. Cite any ideas you take from online sources in your code (include the full URL where you found the idea). You may refer to your own solutions or the master solutions to prior homework assignments from this class as well as any iPython notebooks from this class. Do not put your solution in a public place (e.g., a public GitHub repo).
Acknowledgements
This assignment is very lightly modified from one created by Philipp Krähenbühl.